fpga加速yolo方案调研
概念理解
ai应用的目标是是实现特定功能的神经网络模型、
在Pytorch中模型进行训练和推理通常涉及以下步骤:
- 准备数据:加载训练和验证数据集。
- 定义模型:创建一个深度学习模型。
- 定义损失函数:选择合适的损失函数。
- 定义优化器:选择合适的优化器来更新模型参数。
- 训练过程:迭代数据,进行前向计算、计算损失、反向传播和参数更新。
- 保存模型:在训练过程结束或满足某个条件时保存模型参数。
- 进行推理:使用训练好的模型进行预测或推理。
以下是一个简单的Pytorch训练和推理的例子:
1 | |
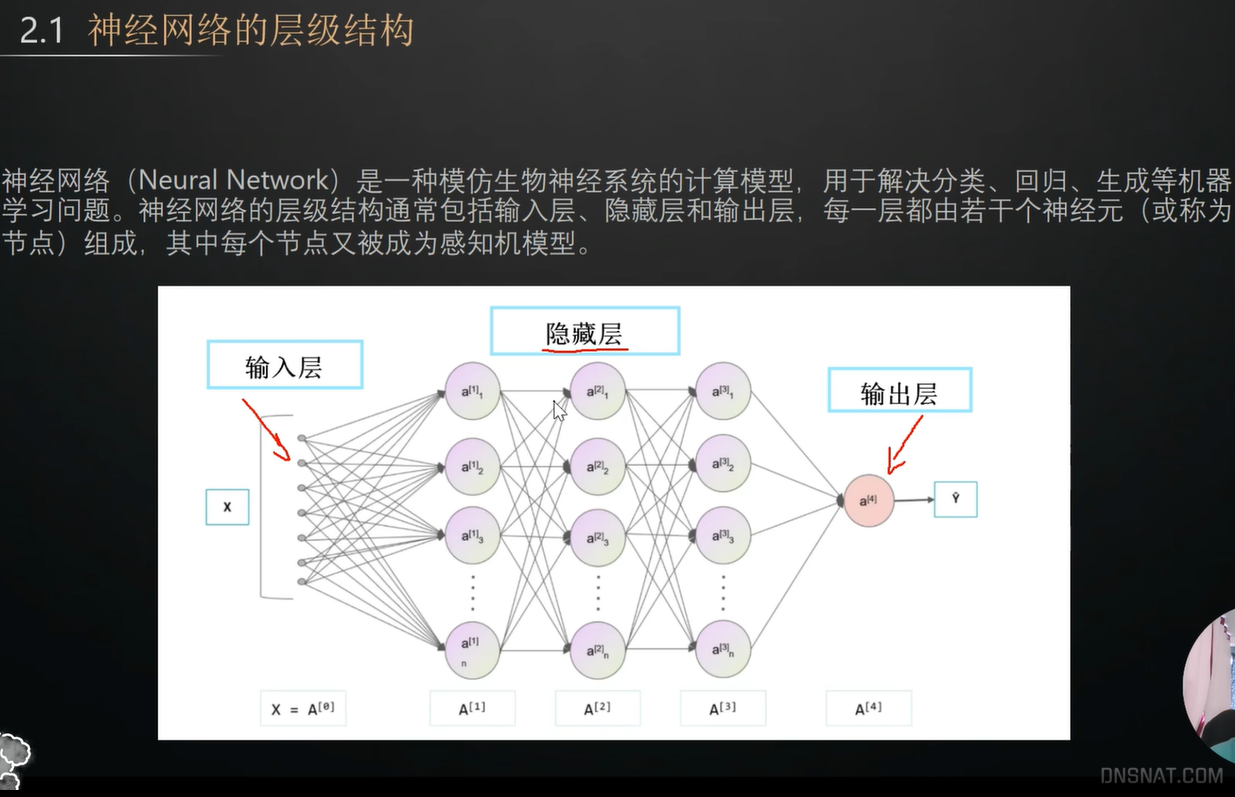
神经网络的层级结构
加速方案
pc加速有gpu,嵌入式中加速有npu、还有就是fpga这种通用硬件。FPGA的低延迟优势主要来自于其并行处理能力、硬件级定制化、实时性、高带宽连接、架构差异、开发和优化难度以及计算资源利用率等方面。而NPU虽然在某些方面也具有低延迟特性,但在这些方面可能不如FPGA表现出色。如果运行的算法和模型确定,且商用的发货规模足够大,足够可以摊薄一次性研发和投片的成本,那么ASIC的NPU将是首选,因为相比之下,FPGA价格昂贵,速度较慢且功耗相对更高。但是目前很多应用场景例如自动驾驶,使用的神经网络算法并不确定,而且制造工艺往往要求非常高,所以一次性研发和投片成本很高,使用ASIC便不是最经济实惠的方式。
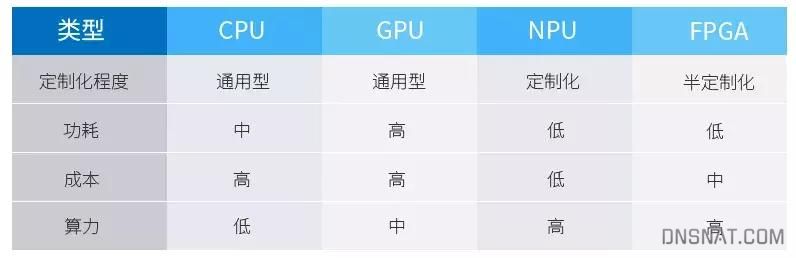
CPU/GPU/NPU/FPGA各自的特点
YOLOv5的速度最快可以达到每秒140帧(FPS),zynq7020 轻量加速能做到100ms 大概10帧左右。
FPGA Zynq7020 上的轻量级YOLO 目标检测演示与介绍
ai自瞄2070以上能1ms 人类的极限也就在100ms左右
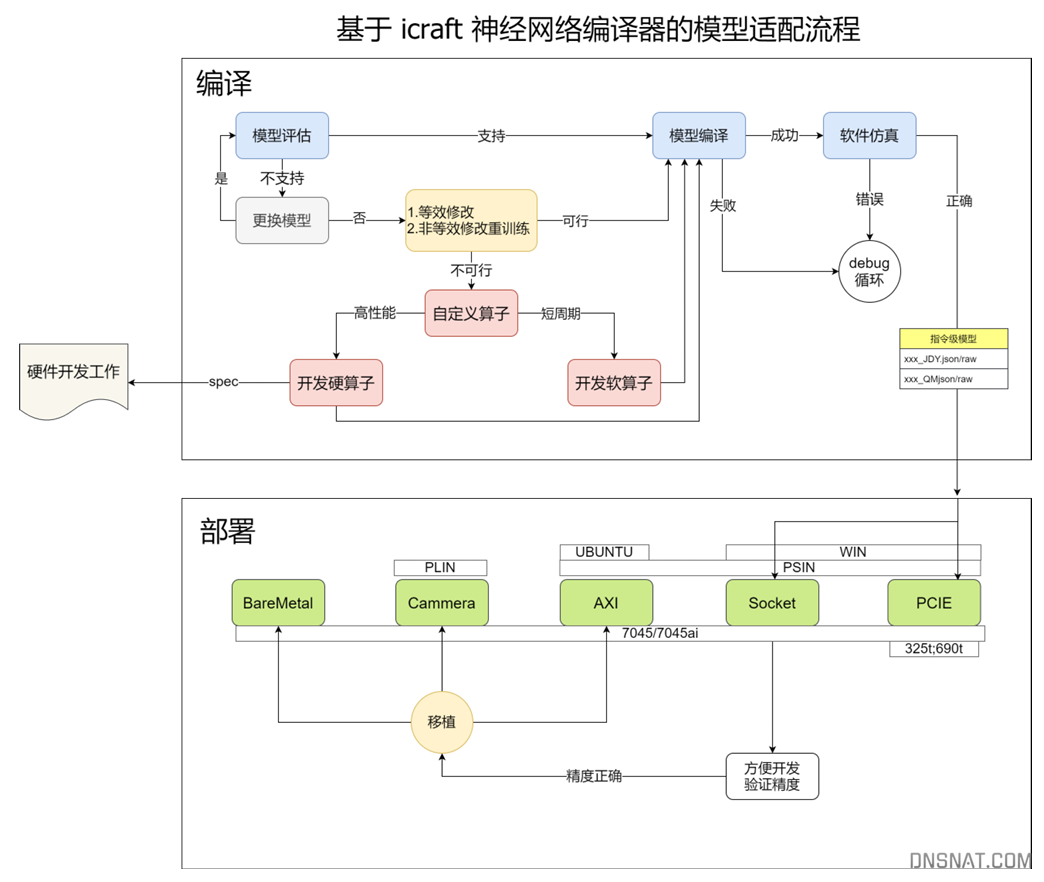
对于yolo的加速并没有统一标准的方案,根据不同的硬件情况、部署复杂情况、需求情况的应用不用的加速方案。而且各种加速方案也在不断的迭代和升级。
fpga加速大体分为两种方案:
一、完全自己设计,开发硬件算子,修改软件框架中对应接口为硬件接口。主要思路为fpga实现dsp,但是否比cpu neon有优势还需斟酌。
二、各个fpga厂家实现的系统方案。例如复旦微Icraft、xilinx vitis ai等,实现了标准算子库进行加速。系统方案有个缺点是并不支持通用fpga硬件。
一、HLS方式
需理解yolo的实现组成,找出计算时间消耗大的部分。把这个c++通过hls方式转换成fpga的ip核,通过pcie或者axi等通道调用这个ip进行加速。
dhm2013724/yolov2_xilinx_fpga: 在 Xilinx 的 FPGA Pynq/zedBoard 中加速 YOLOv2 的演示
HLS(High-level synthesis)的开源CNN加速库,如hls4ml和FINN。
-
HLS方式对比vitis ai大板子的优势是低成本方案。
ONNX-to-Hardware Design Flow for the Generation of Adaptive Neural-Network Accelerators on FPGAs.pdf
基于ZYNQ的+Yolo+v3-SPP实时目标检测系统_光学+精密工程.pdf
针对Yolo V3-SPP和Yolo V3-Tiny网络结构,检测速度分别为38.44 FPS和177FPS
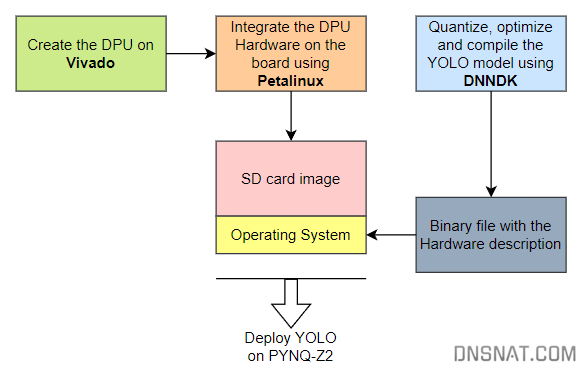
二、DNNDK方式
https://andre-araujo.gitbook.io/yolo-on-pynq-z2
DNNDK which stands for Deep Neural Network Development Kit. This is a set of tools developed by Xilinx to accelerate the development and implementation of Deep Neural Networks (DNN’s) on Xilinx FPGA devices. This development kit was specially designed to take advantage of the power of parallel processing and reconfigurable flexibility of the FPGA’s to accelerate machine learning tasks and DNN inference.
This tool will be essential on the development of a object detector because it will be responsible to compress the YOLO model to fit the PYNQ-Z2 requirements. Also, the resulting file will communicate directly with the DPU to accelerate the Neural Network and make a very quick inference.
三、VITIS AI方式
vitis ai教程
Microsoft ONNX Runtime 是聚焦 ONNX 模型的开源推断加速器。Vitis AI 已集成该平台,从而为可从各种训练框架导出的 ONNX 模型提供最强大的支持。它在 Python 和 C++ 中整合了最易于使用的运行时 API,无需 TVM 所要求的独立编译阶段即可支持模型。在 ONNXRuntime 中包含分区器,可在 CPU 和 FPGA 之间自动进行分区,从而进一步增强模型部署便利性。最后,它还整合了 Vitis AI 量化器,且无需独立量化设置。
要阅读了解有关 Microsoft ONNX Runtime 的更多信息,请访问 https://microsoft.github.io/onnxruntime/。
Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial at 1.4 · Xilinx/Vitis-AI-Tutorials
vitis对比DNNDK
Vitis AI is Xilinx’s new version of the tools, there will be no more dnndk releases going forward.Vitis AI allows for a unified build flow for edge appplications using (Zynq and ZynqUS+), as well as Alveo boards (for cloud and data center applications).The Vitis AI flow still used decent and dnnc under the hood for edge based applications, so the flow is very similary to dnndk.Vitis AI is avaliable on GitHub at https://github.com/Xilinx/Vitis-AI, instead of at xillin.com (like dnndk), and docker containsers are supplied to to run the tools.There are 3 API flow for Vitis AI, and the dnndk legacy sw examples are still supported. See the following UGs for more
zynq-7000支持情况
Zynq-7000 is not tailored for Machine Learning applications. While the use of this device is technically possible the performance is unsatisfactory.
For this reason, no tutorials or new images have been developed for the ZC706 card or other cards that target the Zynq-7000 family.
Support for Zynq-7000 devices has been officially discontinued starting with Vitis AI 1.4.
The recommended Machine Learning Application Starter Kit is the affordable KRIA KV260 which has been designed for advanced vision application development, without requiring complex hardware design knowledge.
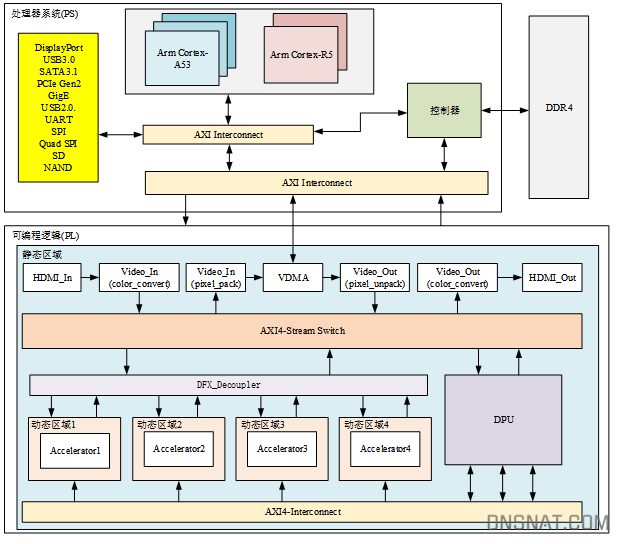
软件加速方案
一、LibTorch和C++
针对简单模型或需频繁变动模型,LibTorch因其灵活性和便捷性更胜一筹。
LibTorch支持的模型格式为pt和pth,其中pt是PyTorch原生格式,pth是Python序列化格式。
二、TensorRT和ONNX
然而,若追求极致性能,ONNX结合TensorRT则成为首选。
三、 Matlab
MATLAB® Coder™ 与 Deep Learning Toolbox 结合使用,从经过训练的深度学习网络生成 C++ 代码。然后您可以将生成的代码部署到使用 Intel® 或 ARM® 处理器的嵌入式平台。您还可以从不依赖任何第三方库的经过训练的深度学习网络生成泛型 C 或 C++ 代码。
四、补充说明linux实时补丁
在线程数较少,且线程运行时间较短的情况下,性能差异并不明显,但如果线程数较多,且运行时间较长时,对于非实时系统,个别线程的时延能达到ms级,而对于实时系统来说,平均时延还是保持在20us左右,所以对于实时性要求较高的系统,我们还是应该给linux内核打上实时的补丁!
CPU、GPU、NPU推理速度比较
(1)CPU
YOLOv5 Python-3.8.17 torch-1.8.2+cu111 CPU
1 | |
平均时间为1.3436 s
YOLOv5 Python-3.7.9 torch-1.13.1+cpu CPU
1 | |
平均时间为0.5475 s
(2)GPU
YOLOv5 Python-3.8.17 torch-1.8.2+cu111 CUDA:0 (NVIDIA GeForce RTX 4060 Laptop GPU, 8188MiB)
1 | |
平均时间为0.0309 s
(3)NPU
运行十张所分别用到的时间
1 | |
平均时间为69.54544 ms = 0.06954544 s
yolo环境搭建
安装yolo v5 依赖
pip install -r .\requirements.txt
安装pytoch和cuda
参考:2024小白安装Pytorch-GPU版(Anaconda,CUDA,cuDNN讲解)_pytorch安装-CSDN博客
pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu121
运行demo测试
python .\detect.py –source D:\workspace\yolov5\data\images\bus.jpg
如果运行出现以下错误,可以卸载torch torchvision重新安装。
NotImplementedError: Could not run ‘torchvision::nms’ with arguments from the ‘CUDA’ backend
pip uninstall torch torchvision torchaudio
基于FPGA实现了类YOLO的轻量化的CNN加速器_fpga yolo-CSDN博客
HLS实现YOLO神经网络系列(一)_hls 神经网络-CSDN博客
Xilinx Vitis AI量化部署Yolov5至DPU (PYNQ)_xilinx dpu-CSDN博客
如何将pytorch的深度学习模型移植到fpga上_mob649e8159b30b的技术博客_51CTO博客
基于FPGA的一维卷积神经网络CNN的实现(一)框架_fpga cnn-CSDN博客
EDRCA-YOLO动态重构目标检测硬件加速器系统方案 - 与非网
浅谈非内存对抗类和AI自瞄类FPS作弊程序原理及常用反反作弊措施与反作弊应对手段(下)_双机ai自瞄-CSDN博客
神经网络视觉AI“后时代”自瞄实现与对抗_ai自瞄-CSDN博客
yolov5推理(libtorch、onnxruntime、opencv、openvino、tensorrt)_onnxruntime 推理 yolv-CSDN博客
