hls4ml核FINN加速框架对比
HLS简要介绍
ESL(Electrical system Level,电子系统级)设计的发展历经多个时期,从早期的CAD(Computer Aided Design)、CAE(Computer Aided Engineering),到EDA (Electronic Design Automation)时代以Verilog和VHDL工具为主,再到现如今的ESL。与传统的RTL(寄存器传送级)设计相比,该方法具有更高的抽象级别,强调系统级建模,称为高层次综合,典型的设计工具如Vivado HLS,使用C/C++作为开发语言,经HLS编译器将设计转换为等价的RTL设计,作为IP供硬件开发人员使用。
HLS开发具有以下优势:
- 在C/C++层面开发算法。在相比verilog或VHDL语言更高抽象程度的C/C++进行算法开发,并转换成相应的RTL实现,设计周期更短。
- 在C级别验证算法的功能正确性。包含c test bench验证源代码的功能正确性,通过C Simulation进行验证;在C-RTL Co-Simulation中复用c test bench,验证程序在模拟器上的正确性;
- 通过优化指令控制RTL综合。对C源代码的变量、循环或端口等添加directives,实现在RTL级别的优化,相比RTL实现更具灵活性。典型优化如循环展开的层数、流水化的深度、数组的包装等。
- 通过优化指令从c源代码创建多个解决方案。一份C源代码可以包含不同的Solution,添加不同的Directives观察对比结果,快速探索设计的不同优化空间。
在Vivado HLS中编写的源代码经过以下步骤进行编译转换:
- 调度。提取源代码的操作逻辑,设置执行顺序。
- 提取控制逻辑,转换为有限状态机(FSM)。
- 绑定,将高层次操作逻辑映射到低层次硬件资源。
HLS的典型设计流如图:
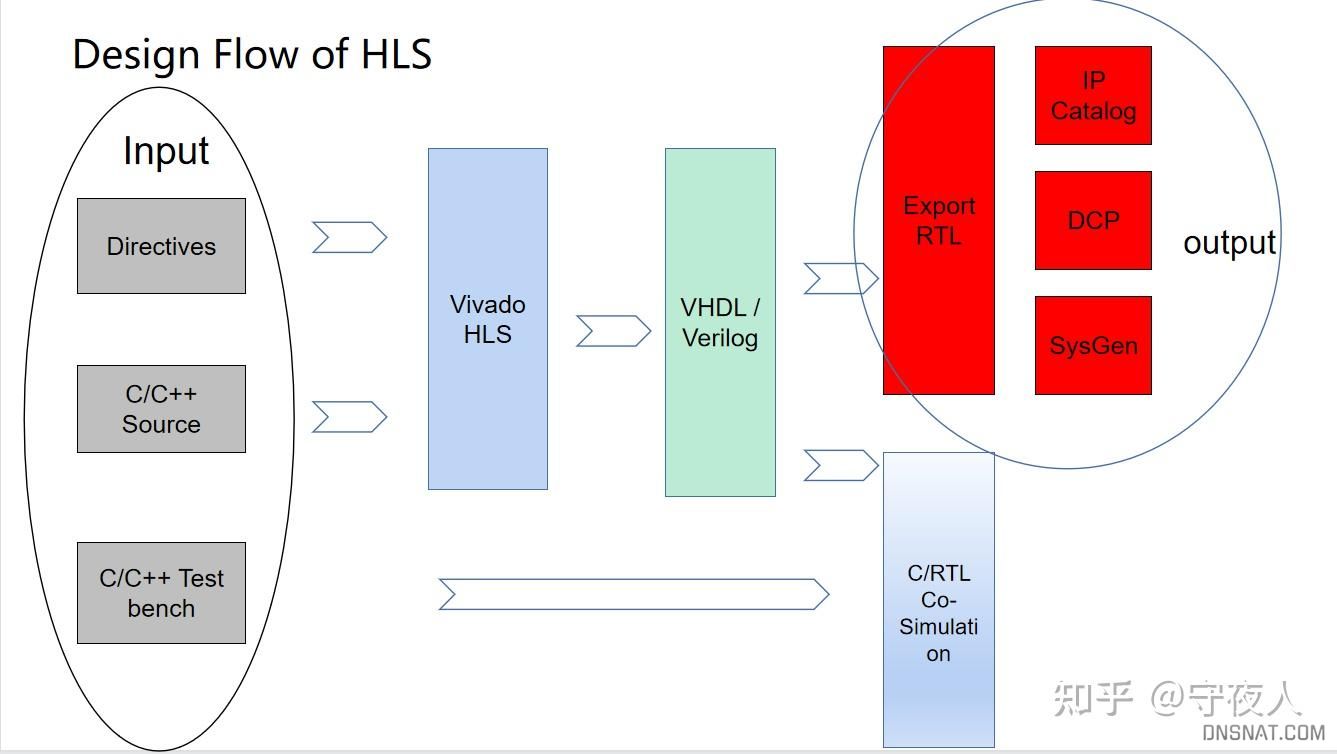
HLS设计流
HLS有三个输入:
- C/C++源代码:对算法的计算描述。
- Directives:优化指令,设置如循环展开的层数、参数类型等。可以加在源代码中,也可以新建不同solution,设置不同优化指令。
- C/C++ Test bench:用于算法的仿真验证,需要自己设置和golden data的对比。
HLS与C++十分相似,Xilinx的Vivado HLS在C++基础上进行了一定修改:
- 支持任意精度数据类型。Vivado HLS支持C原本的数据类型如char、short、int、float、double。其引入了任意精度类型,甚至打破了8位对齐的限制,可以声明23bit的整数或几百位的整数。针对定点数,ap_[u]fixed<W,I,Q,O>中的W是指总共的位数;I是正数部分的位数,W-I就是小数部分的位数;Q是量化模式,针对低位部分;O是溢出模式,针对高位部分。多种模式可参考Xilinx的HLS手册。
- 不支持动态内存申请,内存需在编译时完全确定,不支持运行时申请。
- 不支持C++中的STL。
- 不支持递归。
- 不支持操作系统层面的任何调用,如printf。这个很直观,因为C++在CPU运行,HLS的target是FPGA。
hls4ml
基本信息
项目地址:https://github.com/fastmachinelearning/hls4ml 700+stars 目前仍在维护
开发者:美国哥伦比亚大学、MIT等顶尖高校,最初是为高能物理中的相关需求开发
相关论文:FAHIM F, HAWKS B, HERWIG C, et al. hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices[J]. arXiv, 2021.
AARRESTAD T, LONCAR V, GHIELMETTI N, et al. Fast convolutional neural networks on FPGAs with hls4ml[J]. Machine Learning: Science and Technology, 2021, 2(4): 045015.\
支持网络:
| Architectures/Toolkits | Keras/TensorFlow/QKeras | PyTorch | ONNX |
|---|---|---|---|
| MLP | supported | supported | supported |
| Conv1D/Conv2D | supported | in development | in development |
| RNN/LSTM | in development | in development | in development |
运行平台:Linux, and supports Vivado HLS versions 2018.2 to 2020.1
工作流
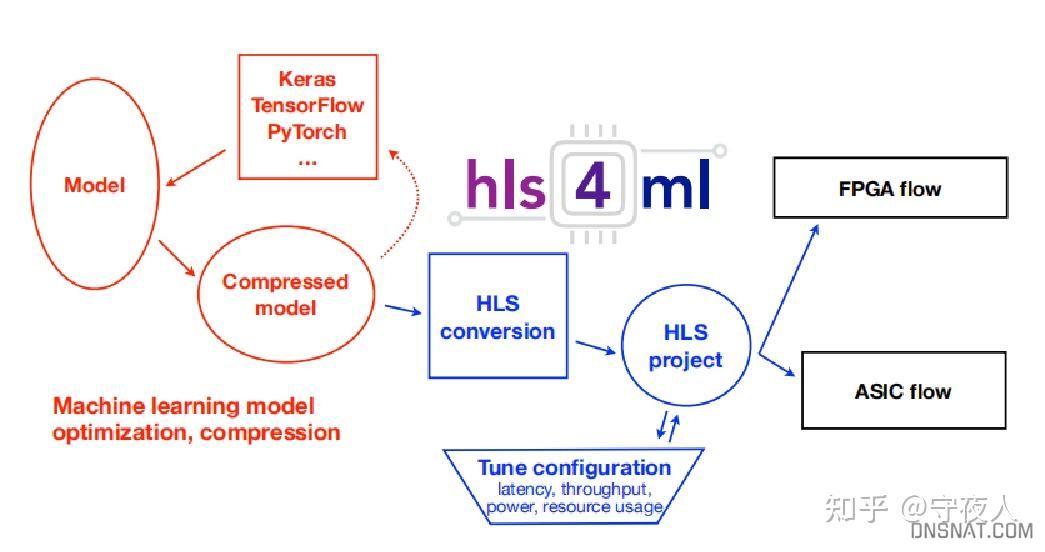
hls4ml工作流
- 在深度学习框架中进行的模型训练和压缩(支持剪枝和量化)
- hls4ml执行,将一个模型转换为一个HLS项目
- 在FPGA或ASIC上综合并实现
每个层和激活类型都实现为一个单独的可配置模块,定制以执行特定的操作。网络的每一层的计算都在单独的硬件中进行,完整的模型被合成到一个IP核心中,可以集成到一个完整的应用程序中。
项目架构
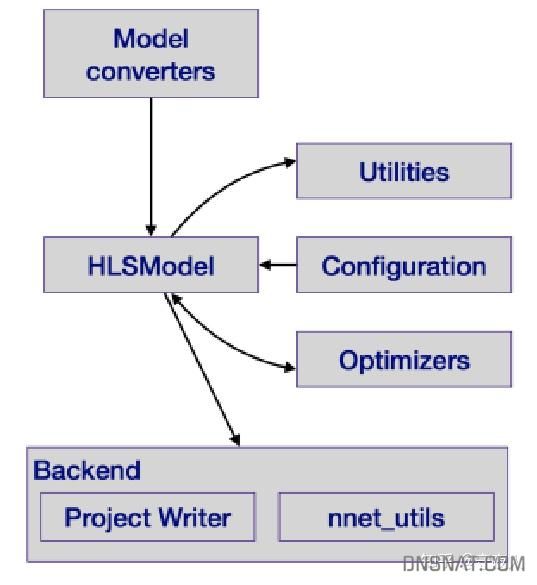
hls4ml的项目组成
- Model converter:(Q)Keras, TensorFlow, PyTorch, and ONNX导入
- Utilities:对神经网络图的可视化工具、指导用户设置的工具(如bit位宽)
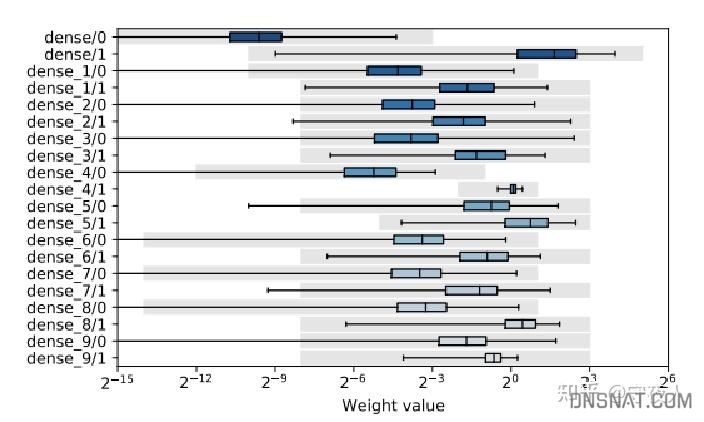
可视化工具。使用箱型图将原本的weight、bias参数分布画出,灰色为用户配置的数据精度的表示范围。
- Configuration:时钟周期,IO类型,位宽,重用因子等
- Optimizers:修改网络图结构,使其更轻量级、快速推理。如batchnorm层的融合
关键设计
- 并行:dense层与conv层实现的核心是矩阵-向量乘法。设置重用因子,表示计算一个层的输出值使用乘法器的次数。对于较大的重用因子,矩阵向量乘法内核具有更大的延迟和II,但使用更少的片上资源
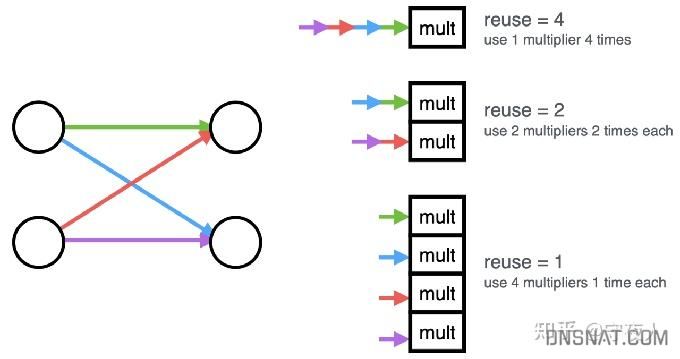
reuse为重用因子
- 稀疏:包含两种稀疏矩阵向量乘法kernel,两种实现互补,适用于不同场景。
- 第一个实现:使用HLS预处理器指令基于非零权值的数量来限制内核可用的乘法器的数量,剩下HLS进行优化。这只适用于较小的网络层
- 在第二个实现中,使用COO表示来压缩非零权值,其中索引被打包到权值本身中。hls4ml用户可以为每层指定一个布尔压缩参数,从而激活这个内核。
测试
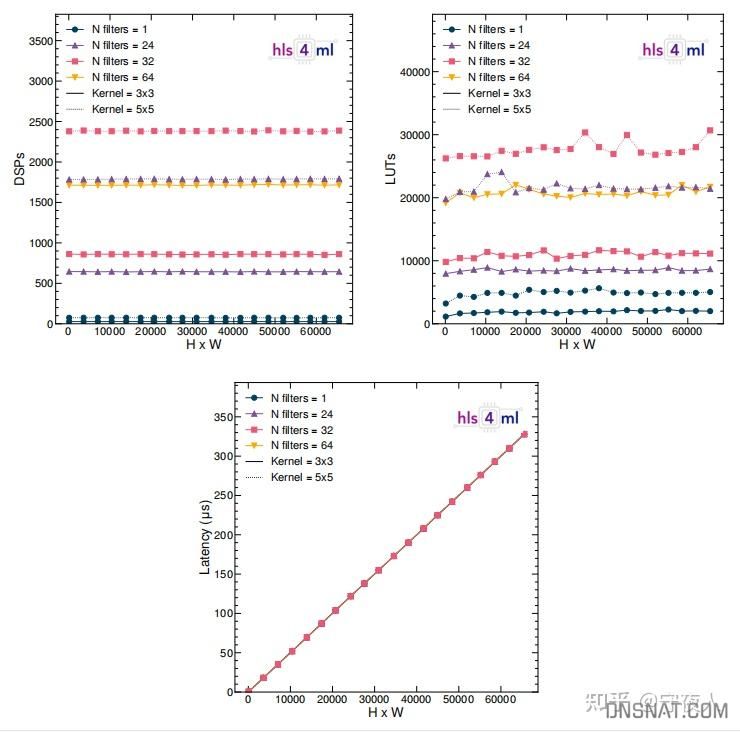
- 不同filter数量和kernel大小的单个卷积层的输入大小的关系
- 模型深度与资源消耗和延迟的关系
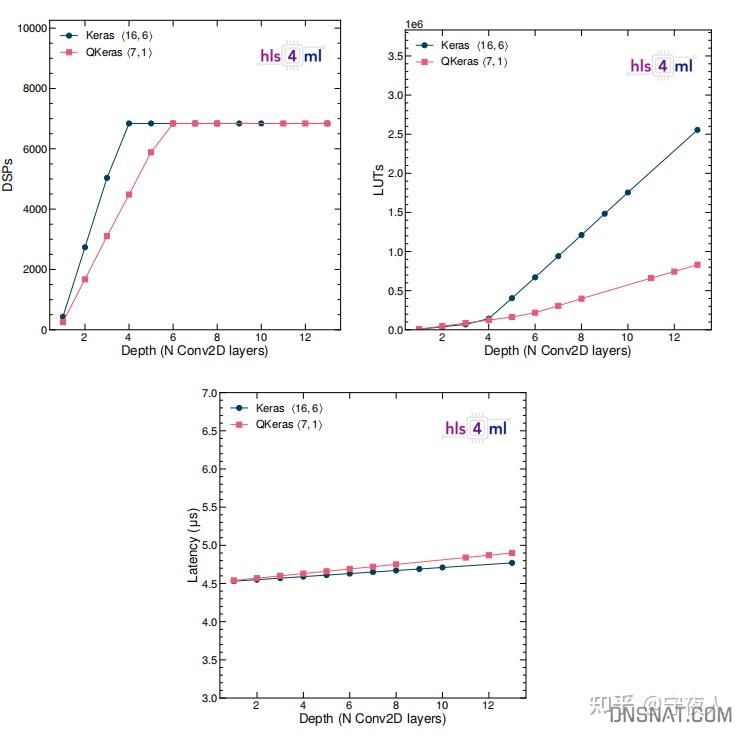
这些测试都比较直观,论文中有其他更多不同调优设置的实验对比。奇怪的是,论文中对比和其他HLS加速器的实验缺失。
FINN
基本信息
项目地址:https://github.com/Xilinx/finn 420+ stars 仍在维护
开发者:Xilinx官方和FINN社区,对Xilinx的许多FPGA型号适配
相关论文:UMUROGLU Y, FRASER N J, GAMBARDELLA G, et al. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference[C]// Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017: 65–74.
BLOTT M, PREUSSER T, FRASER N, et al. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks[J]. arXiv, 2018.
运行平台:Linux, Vitis ( Vivado HLS的升级版,用法几乎不变)
项目架构

finn-examples:是用例仓库,包含多种经典网络如VGG、Resnet、MobileNet,多个硬件平台Pynq-Z1、ZCU104、Ultra96、多个数据集CIFAR-10、MINST、ImageNet,多种量化方式1bit、2bit、4bit、8bit weights or activations。
brevitas:Xilinx开发的基于Pytorch的量化感知训练工具包。
finn-hlslib:FINN硬件部分HLS实现库。支持高度可配置的C++模板参数:Input, weight, output数据类型,不同FPGA资源的映射(LUT or DSP, LUTRAM or BRAM)。
软硬件设计
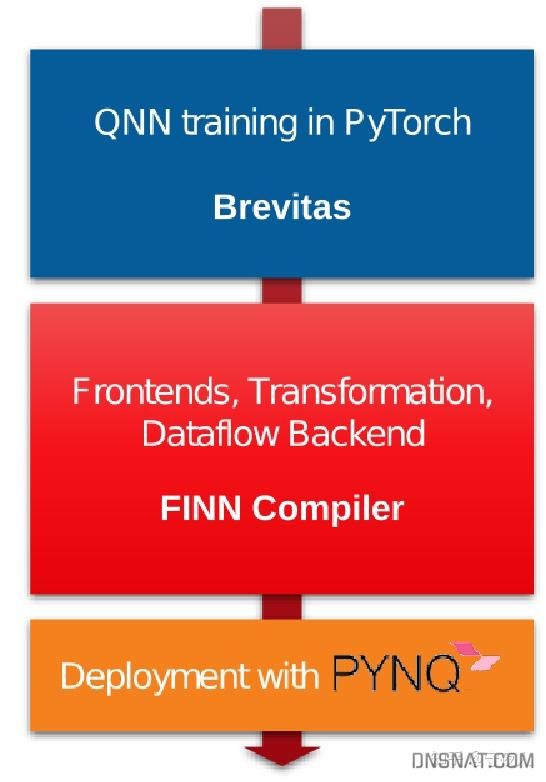
FINN编译器分为三个层次:
- 前端:将框架训练的qnn转换为FINN IR,获取网络的结构与数据类型精度。
- IR:每个节点都有其输入、参数(权重)和输出的量化标记,以实现量化感知优化,以及为量化计算优化的后端原语的映射。包含FPGA资源分析、FPGA数据流架构生成、FPGA多层卸载调度生成等。
- 后端:使用IR图和特定后端信息创建一个部署包,部署包包括QNN模型的参数数据,以及执行模型的后端特定代码,包括运行时环境、用于针对数据流和多层卸载体系结构的可执行硬件设计,以及预定义平台的选择。
FINN加速器是HLS硬件库,可将卷积、全连接、池化和 LSTM 层类型作为流组件实现。该库使用 C++ 模板来支持广泛的精度。
加速器架构
FINN将加速器分为两种架构,并且支持这两种架构。
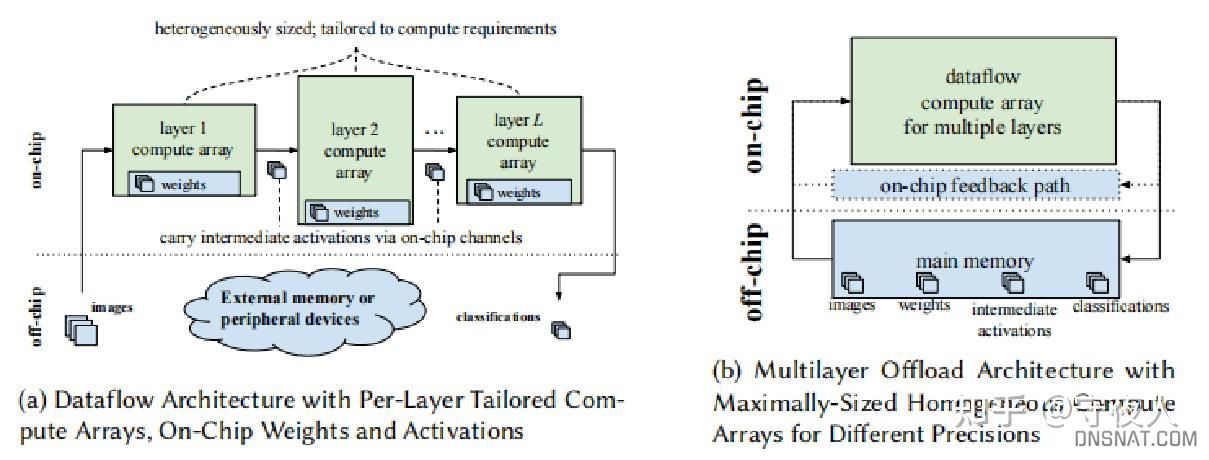
- 数据流架构:为特定的神经网络拓扑定制,每一层的激活和权重的精度不同。每层实例化一个计算引擎。一旦上一个引擎开始产生输出,引擎就开始计算,因此在层之间引入另一种并发性.
- 多层卸载结构:相当于取数据流架构中计算资源的并集,适用于在有限资源约束下的大型网络
数据流架构成本是所有实现层的总和,而多层架构的成本是由层的最大值定义的。显然前者的延迟更低,但资源开销更大。
工作流
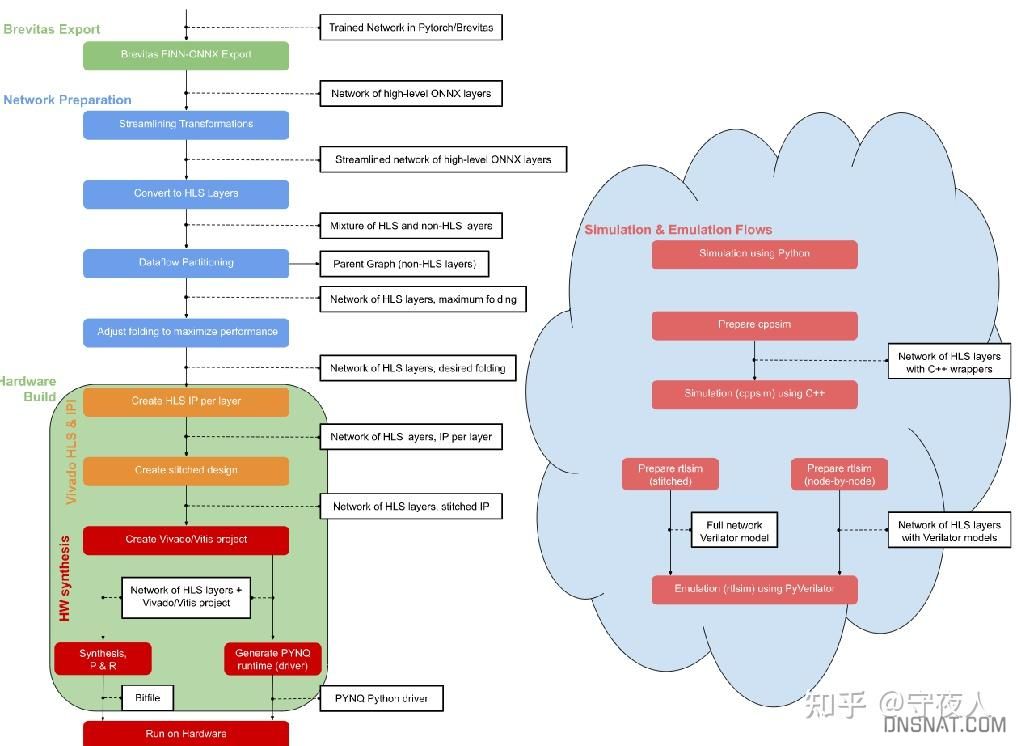
- 导入Brevitas量化后的模型
- 网络准备 ,优化网络并将节点转换为与finn-hlslib函数对应的自定义节点
- 硬件构建和部署:1.驱动程序生成。2.DMA 和 DWC 节点插入:用于将数据移入和移出加速器(来自 DRAM)的 DMA 引擎,以及在需要的连续节点之间的数据宽度转换器。3.用于平面规划的分区。4.FIFO插入和IP生成。5.Vivado/Vitis 项目生成和综合
测试
测试网络都经过一定修改,如yolo将第一层与最后一层卷积8位,其他卷积1位权重三位激活。
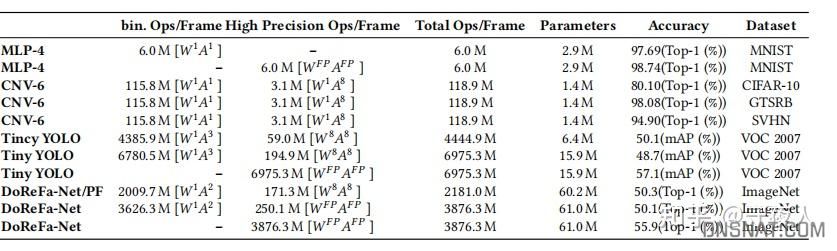
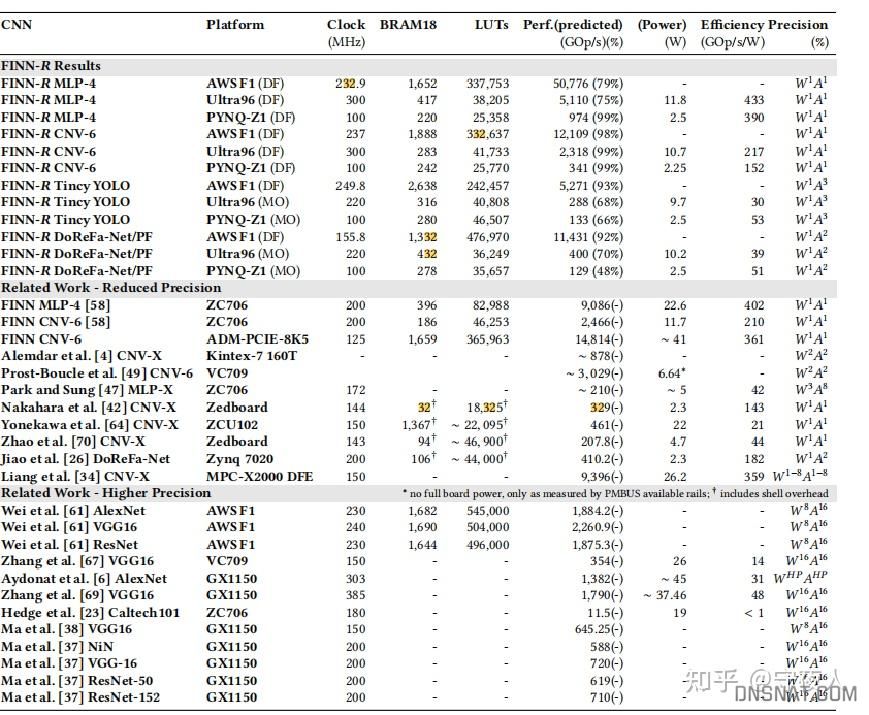
CNNA
基本信息
这是一个较小的实现,代码也许久未更新,可以作学习之用,前两个项目文档、代码、论文、教程齐全,可以拿来即用。
代码地址:https://github.com/jonathan93sh/CNNA 2年前最后更新
相关论文:BJERGE K, SCHOUGAARD J H, LARSEN D E. A scalable and efficient convolutional neural network accelerator using HLS for a System on Chip design[J]. arXiv, 2020.
主要贡献
1.通用的CNN架构,包括单计算引擎,带有5个核心元素(weight buffer、data buffer、PEA(PEs Array)、pooling block output handler).
2.在训练过程中采用动态自动缩放的方法,使浮点和量化定点加速器之间的精度差降到最低
3.拼接用于过大而不能在单个处理通道中执行的卷积层,并用于将复杂的卷积分割为子卷积。
4.提出了一种具有可执行模型的基于模板的SystemC设计方法,用于设计空间探索。该模板模型通过HLS合成到Xilinx IP核中,并使用PYNQ框架和Python从主机CPU进行控制。
关键设计
设计空间探索,包括:
- 定点数的位宽格式,如I+F,对精度有影响。
- 内部带宽
- PE的数量
- 输出带宽
- cache的kernel数量
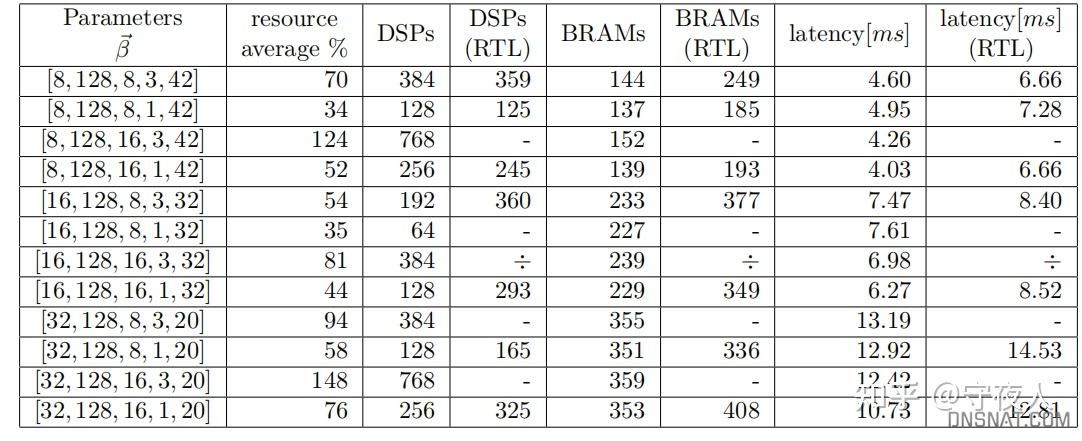
Parameter为上述5个参数的组合,具体见论文
工作流
- 预处理:将weight转换为定点数,调整和缩放权重。计算参数,例如层输出大小和待分割的层,离线计算。最后,权重被保存在h5文件中,可以传输至硬件目标。
- 初始化:硬件目标需要配置和优化为特定定点数表示,使用优化CNNA的bit文件。首先计算缓冲区大小并获取加载的CNNA的属性。完成此操作后,SW将分配所需的资源,并通过为CNN中的每一层分配缓冲区为SW做好推理准备。
- 推理:支持卷积、最大值池化、全连接层。
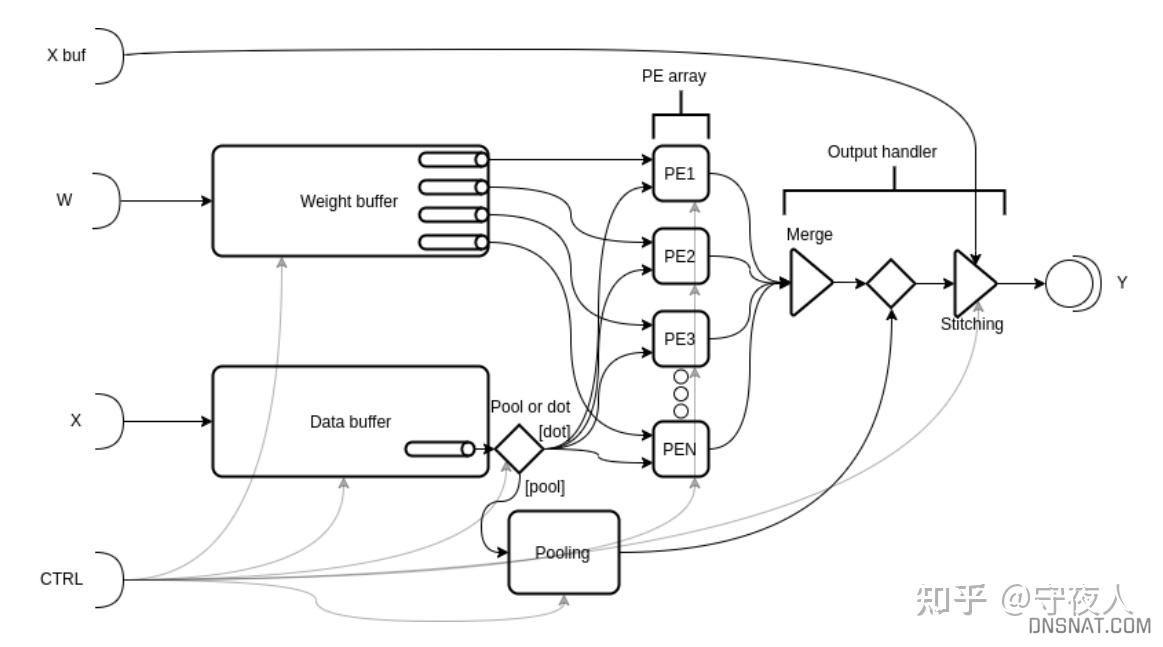
硬件架构
测试
作者仅采用了VGG16测试,具体见论文。
hls4ml和FINN对比
FINN实现了一套rtl版本框架,例如hls-rtllib库。真实工程当中用完全用hls加速的少,更多是verilog编写加速模块。
hls4ml主要是通过onnx转化为hls工程。
其他开源库
- CHaiDNN:https://github.com/Xilinx/CHaiDNN Xilinx官方推出,但4年未更新代码,已经废弃了。
- FlexCNN: https://github.com/UCLA-VAST/FlexCNN 论文:SOHRABIZADEH A, WANG J, CONG J. End-to-End Optimization of Deep Learning Applications[C]// Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside CA USA: ACM, 2020: 133–139.
- fpgaConvNet:https://github.com/AlexMontgome
