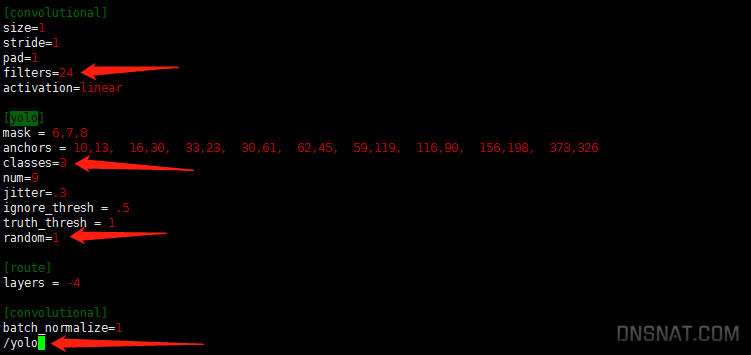
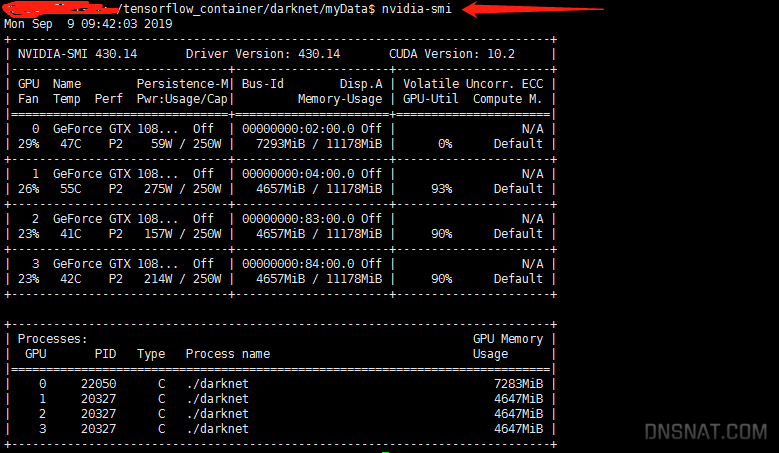
+-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
cuda:extra/cuda 12.6.1-1 (1.7 GiB 4.7 GiB)
cuda安装
yay -s cuda
1.拉取darknet
1 2
git clone https://github.com/pjreddie/darknet cd darknet
ARCH= -gencode arch=compute_50,code=[sm_50,compute_50] \ -gencode arch=compute_52,code=[sm_52,compute_52] # -gencode arch=compute_20,code=[sm_20,sm_21] \ This one is deprecated?
for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else: fval.write(name) else: ftrain.write(name)
for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult)==1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) +" "+" ".join([str(a) for a in bb]) +'\n')
wd = getcwd()
for year, image_set in sets: if not os.path.exists('myData/labels/'): # 改成自己建立的myData os.makedirs('myData/labels/') image_ids = open('myData/ImageSets/Main/%s.txt'%(image_set)).read().strip().split() list_file = open('myData/%s_%s.txt'%(year, image_set),'w') for image_id in image_ids: list_file.write('%s/myData/JPEGImages/%s.jpg\n'%(wd, image_id)) convert_annotation(year, image_id) list_file.close()