Windows Python实现方式 SplitCap是按照会话流来切割的工具,会话流由源IP、目的IP、源端口、目的端口四个部分组成。
参考github连接:
https://github.com/echowei/DeepTraffic/tree/master/1.malware_traffic_classification
该链接有Splitcap工具
1、Split切分会话流 Split切分pcap文件脚本(PowerShell)如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 foreach($ f in gci 1 _Pcap *.pcap)0 _Tool\SplitCap_2-1 \SplitCap -p 100000 -b 100000 -r $ f.FullName -o 2 _Session\AllLayers\$ ($ f.BaseName)-ALL 0 _Tool\SplitCap_2-1 \SplitCap -p 100000 -b 100000 -r $ f.FullName -s flow -o 2 _Session\AllLayers\$ ($ f.BaseName)-ALL 2 _Session\AllLayers\$ ($ f.BaseName)-ALL | ?{$ _.Length -eq 0 } | del0 _Tool\SplitCap_2-1 \SplitCap -p 100000 -b 100000 -r $ f.FullName -o 2 _Session\L7\$ ($ f.BaseName)-L7 -y L70 _Tool\SplitCap_2-1 \SplitCap -p 100000 -b 100000 -r $ f.FullName -s flow -o 2 _Session\L7\$ ($ f.BaseName)-L7 -y L72 _Session\L7\$ ($ f.BaseName)-L7 | ?{$ _.Length -eq 0 } | del0 _Tool\finddupe -del 2 _Session\AllLayers0 _Tool\finddupe -del 2 _Session\L7
2、提取会话内容 对SpiltCap进行预处理,提取传输层以上的payload并进行拼接,脚本(PowerShell)如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 $SESSIONS_COUNT_LIMIT_MIN = 0 $SESSIONS_COUNT_LIMIT_MAX = 6000 $TRIMED_FILE_LEN = 784 $SOURCE_SESSION_DIR = "2_Session\L7" echo "If Sessions more than $SESSIONS_COUNT_LIMIT_MAX we only select the largest $SESSIONS_COUNT_LIMIT_MAX ." echo "Finally Selected Sessions:" $dirs = gci $SOURCE_SESSION_DIR -Directory foreach ($d in $dirs )$files = gci $d .FullName$count = $files .countif ($count -gt $SESSIONS_COUNT_LIMIT_MIN )echo "$ ($d .Name) $count " if ($count -gt $SESSIONS_COUNT_LIMIT_MAX )$files = $files | sort Length -Descending | select -First $SESSIONS_COUNT_LIMIT_MAX $count = $SESSIONS_COUNT_LIMIT_MAX $files = $files | resolve-path $test = $files | get-random -count ([int ]($count /10 ))$train = $files | ?{$_ -notin $test } $path_test = "3_ProcessedSession\FilteredSession\Test\$ ($d .Name)" $path_train = "3_ProcessedSession\FilteredSession\Train\$ ($d .Name)" ni -Path $path_test -ItemType Directory -Force ni -Path $path_train -ItemType Directory -Force cp $test -destination $path_test cp $train -destination $path_train echo "All files will be trimed to $TRIMED_FILE_LEN length and if it's even shorter we'll fill the end with 0x00..." $paths = @ (('3_ProcessedSession\FilteredSession\Train' , '3_ProcessedSession\TrimedSession\Train' ), ('3_ProcessedSession\FilteredSession\Test' , '3_ProcessedSession\TrimedSession\Test' ))foreach ($p in $paths )foreach ($d in gci $p [0 ] -Directory ) ni -Path "$ ($p [1])\$ ($d .Name)" -ItemType Directory -Force foreach ($f in gci $d .fullname)$content = [System.IO.File ]::ReadAllBytes($f .FullName)$len = $f .length - $TRIMED_FILE_LEN if ($len -gt 0 )$content = $content [0 .. ($TRIMED_FILE_LEN -1 )] elseif ($len -lt 0 )$padding = [Byte []] (,0 x00 * ([math ]::abs($len )))$content = $content += $padding Set-Content -value $content -encoding byte -path "$ ($p [1])\$ ($d .Name)\$ ($f .Name)"
结果如下,左侧bin文件是提取的会话流,右侧是网络数据流的通信层级,可见绘话流就是TCP层之上的payload。
3、会话流转为png图片 文件的内容就是字节序,将字节转为16进制为一个单位的数组,然后将两个数组成员拼接为一个字节,字节转为Int存到numpy的array当中,然后reshape一下,让一行为28个数,Python代码如下:
1 2 3 4 5 6 7 8 9 def getMatrixfrom_pcap (filename,width):open (filename, 'rb' ) as f:read ()hexlify (content) array ([int (hexst[i:i+2 ],16 ) for i in range (0 , len (hexst), 2 )]) int (len (fh)/width)reshape (fh[:rn*width],(-1 ,width)) uint8 (fh)
然后在批量处理上一步生成的会话流即可,代码如下:
1 2 3 4 5 6 7 8 9 10 11 paths = [['3_ProcessedSession\TrimedSession\Train' , '4_Png\Train' ] ,['3_ProcessedSession\TrimedSession\Test' , '4_Png\Test' ] ]for p in paths:for i , d in enumerate (os.listdir (p [0] )):.path .join (p [1] , str (i))mkdir_p (dir_full)for f in os.listdir (os.path .join (p [0] , d)):.path .join (p [0] , d, f)print (bin_full).fromarray (getMatrixfrom_pcap (bin_full,PNG_SIZE)).path .join (dir_full, os.path .splitext (f)[0] +'.png' ).save (png_full)
4、将PNG图片转为MNIST格式 首先MNIST数据集格式查看以下连接:
https://blog.csdn.net/qq_20936739/article/details/82011320
文件头:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 header = array('B')header .extend([0 ,0 ,8 ,1 ])header .append(int('0 x'+hexval[2 :][0 :2 ],16 ))header .append(int('0 x'+hexval[2 :][2 :4 ],16 ))header .append(int('0 x'+hexval[2 :][4 :6 ],16 ))header .append(int('0 x'+hexval[2 :][6 :8 ],16 )) data_label = header + data_labelif max([width,height]) <= 256 :header .extend([0 ,0 ,0 ,width,0 ,0 ,0 ,height])else :raise ValueError('Image exceeds maximum size: 256 x256 pixels');header [3 ] = 3 # Changing MSB for image data (0 x00000803)
数据:
1 2 3 4 5 6 7 8 9 10 11 12 for filename in FileList:int (filename )label = int (filename .split('\\' )[2])open (filename )x in range (0,width):in range (0,height):x ])label ) # labels start (one unsigned byte each)"{0:#0{1}x}" .format (len (FileList),6) # number of files in HEX'0x' + hexval[2:].zfill(8)
需要改Name,改为Test和Train,如下:
1 2 Names = [['4_Png\t10k','5_Mnist\\t10k']] [['4_Png\train','5_Mnist\\test']]
将PNG数据处理完,生成IDX-Ubyte格式的数据集,便可以根据神经网络来训练:
值得一提的是,如果数据集中只有7个特征的话,数据集标签的维度还是10,10是通过one-hot形式标识的,只是7,8,9位只显示为0。
然后用CNN对其进行训练,
本代码的运行环境如下:
tensorflow源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 import timeas npas tf if class numer is 2 or 20 , please edit the variable named "num_classes" in /usr/local/lib/python2.7 /dist-packages/tensorflow/contrib/learn/python /learn/datasets/mnist.py argv [1 ]int (sys.argv [2 ])int (sys.argv [3 ])split (DATA_DIR)[1 ]tf .InteractiveSession()tf .app.flags'data_dir' , DATA_DIR, 'Directory for storing data' )function : find a element in a list try :index (element)return index_elementreturn -1 tf .truncated_normal(shape, stddev=0.1 )return tf .Variable(initial)tf .constant(0.1 , shape = shape)return tf .Variable(initial)x , W):return tf .nn .conv2d(x , W, strides=[1 , 1 , 1 , 1 ], padding='SAME' )x ):return tf .nn .max_pool(x , ksize=[1 , 2 , 2 , 1 ], strides=[1 , 2 , 2 , 1 ], padding='SAME' )x = tf .placeholder("float" , [None, 784 ])tf .placeholder("float" , [None, CLASS_NUM])first convolutinal layer5 , 5 , 1 , 32 ])32 ])tf .reshape(x , [-1 , 28 , 28 , 1 ])tf .nn .relu(conv2d(x_image, w_conv1) + b_conv1)5 , 5 , 32 , 64 ])64 ])tf .nn .relu(conv2d(h_pool1, w_conv2) + b_conv2)7 *7 *64 , 1024 ])1024 ])tf .reshape(h_pool2, [-1 , 7 *7 *64 ])tf .nn .relu(tf .matmul(h_pool2_flat, w_fc1) + b_fc1)tf .placeholder("float" )tf .nn .dropout(h_fc1, keep_prob)1024 , CLASS_NUM])tf .nn .softmax(tf .matmul(h_fc1_drop, w_fc2) + b_fc2)tf .argmax(y_, 1 )count = tf .unique_with_counts(actual_label)tf .reduce_sum(y_*tf .log (y_conv))tf .train.GradientDescentOptimizer(1 e -4 ).minimize(cross_entropy)tf .argmax(y_conv, 1 )tf .unique_with_counts(predict_label)tf .equal(predict_label, actual_label)tf .reduce_mean(tf .cast(correct_prediction, "float" ))tf .boolean_mask(actual_label,correct_prediction)tf .unique_with_counts(correct_label)if model exists : restore itelse : train a new model and save ittf .train.Saver()"model_" + str(CLASS_NUM) + "class_" + folder'/' + model_name + ".ckpt" if not os.path.exists (model):tf .initialize_all_variables())if not os.path.exists (model_name):open ('out.txt' ,'a' ) as f :f .write (time.strftime ('%Y-%m-%d %X' ,time.localtime ()) + "\n" )f .write ('DATA_DIR: ' + DATA_DIR+ "\n" )for i in range (TRAIN_ROUND+1 ):50 )if i%100 == 0 :eval (feed_dict={x :batch[0 ], y_:batch[1 ], keep_prob:1 .0 })"step %d, train accuracy %g" %(i, train_accuracy)print (s)if i%2000 == 0 :open ('out.txt' ,'a' ) as f :f .write (s + "\n" )x :batch[0 ], y_:batch[1 ], keep_prob:0 .5 })print ("Model saved in file:" , save_path)else : print ("Model restored: " + model)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cd aifw\2.PreprocessedToolscd aifw\4.TrainAndTest\1d_cnn_25+3cd aifw\5.Invoke
Linux C++实现方式 数据包解析 PCPP这个库将一个原始数据包解析为若干层,每一层的协议信息由一个变量来保存,我们可以自由读写这些解析后的数据。
一个 RawPacket 表示原始的字节流,也就是我们最开始从 pcap 文件中读进来的一个数据包,经过解析,可以将这个数据包拆分成我们熟悉的若干层数据!PCPP的一个特性是它不保存多个副本,而只是在同一个数据包上标记各层协议的起点,这些起点可以由上一层解析结果访问到。
例如这个图中的解析结果,首先是数据链路层的 Ethernet Layer ,它可以看到所有原始数据;由 Ethernet Layer 层扣除它的头部数据,就是整个 IPv4 层的数据;而由 IPv4 层再继续解析,就是 UDP 层啦!这样层层递推,实际上跟学习计算机网络的时候对数据包的解析顺序差不多。
PCPP提供的数据包解析方法有两种,我们分别来看。
首先还是需要先创建一个 reader ,如果你还记得第一章的内容,那就很简单了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <IPv4Layer.h> #include <Packet.h> #include <PcapFileDevice.h> int main (int argc, char * argv[]) getReader ("test_file_1.pcap" );if (!reader)"Cannot determine reader for file type" << std::endl;return 1 ;if (!reader->open ())"Cannot open input.pcap for reading" << std::endl;return 1 ;if (!reader->getNextPacket (rawPacket))"Couldn't read the first packet in the file" << std::endl;return 1 ;close ();delete reader;return 0 ;
上面是程序的基本框架,已经写好了创建Reader、读取第一个数据包 rawPacket 的部分。接下来的所有代码都追加在 Code to write 那块地方~
首先需要创建一个解析后的数据包:
1 2 pcpp::Packet parsedPacket (&rawPacket) ;
在上面的介绍中,我们知道这个解析后的数据包是一层一层的结构,每一层都有一个指向下一层的指针,于是我们可以使用一个循环来遍历这些层:
1 2 3 4 5 for (pcpp::Layer* curLayer = parsedPacket.getFirstLayer (); curLayer != NULL ; curLayer = curLayer->getNextLayer ())
在这个循环中呢, curLayer 就是当前获取到的层了!假如说我们需要使用到TCP层的信息,那就需要用API获取一下当前层的协议,然后判断 curLayer->getProtocol() == pcpp::TCP ,真是有点麻烦!
好在PCPP为我们提供了第二种获取协议层的方法:
1 pcpp::IPv4Layer* ipLayer = parsedPakcet.getLayerOfType <IPv4Layer>();
直接使用 getLayerOfType 这个接口来获取我们想要的层,很酷!
在我接下来的场景中,使用到的是网络层的IP地址和传输层的端口,那么就只需要:
1 2 pcpp::TcpLayer* tcpLayer = parsedPakcet.getLayerOfType <TcpLayer>();getLayerOfType <IPv4Layer>();
当我们获取到某个特定的层之后,就可以来使用这一层的信息了。在VS环境中有自动补全,使用 tcpLayer->getxxxxxx() 这样的格式,一般就能看到这一层包含的信息。例如本次使用较多的有:
1 2 3 IPv4Address ipLayer->getSrcIPv4Address ();uint16_t tcpLayer->getSrcPort ();getTcpHeader ()->synFlag
Copy
这几个API从名字上就很容易看出它们是什么作用!如果想进行更多的解析,可以看参考资料 [1] 和参考资料 [3] 😁
并不成功的会话切分 所谓 会话分割 ,就是说给出一个很大的 pcap 文件,里面有超级多的数据包,我们要把它按照一个个的TCP会话(或者叫TCP连接,whatever)整理好!
这一工作很有意义!TCP会话一般是数据传输的一个基本单元,它以三次握手开始、以四次挥手结束。譬如以前的HTTP协议,传输一个文件就使用一个TCP会话,即使引入了长连接,也是在一个相对完整的语境中(如一个网页的加载)使用一次TCP会话,所以一个TCP会话的背后可能就是用户的一次网络行为!很多基于网络流量的行为分析技术都是基于TCP会话的,学者们提取TCP会话的各种特征信息,然后使用各种模型,希望把网络流量跟它背后的用户行为对应起来 😹 我们今天还做不到这么多啦,但是从 pcap 文件中整理出一个个TCP会话来,还是可以试试的~
实验目标:整理出会话的开始时间和结束时间,可以顺便计算一下时长 。
All right?先讲思路,再说不足,最后慢慢改进。
我基本的思路是使用一个 四元组 来保存连接信息。熟悉TCP的朋友应该知道,一个TCP连接可以由 (SrcIP, DstIP, SrcPort, DstPort) 这个元组唯一确定,其实就是两端的 Socket 啊!
这么一个元组怎么储存呢?我的做法是进行一个简单的字符串拼接:
1 2 3 4 5 string keyTuple =getSrcIPv4Address ().toString () + " " +getDstIPv4Address ().toString () + " " +to_string (tcpLayer->getSrcPort ()) + " " +to_string (tcpLayer->getDstPort ());
Copy
我们要做的是 整理出会话的开始时间和结束时间 ,还记得吗?
我最初的想法是:对每个数据包进行分析,如果数据包中包含 SYN ,说明它是会话的开始,放入一个 map 中;如果数据包中包含 FIN ,说明它是会话的结束,依据这个数据包的四元组从 map 中获取开始时间,然后使用当前数据包的时间作为结束时间,打印!
总的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 #include <iostream> #include <IPv4Layer.h> #include <TcpLayer.h> #include <Packet.h> #include <PcapFileDevice.h> #include <set> #include <map> #include <ctime> #include <cstdlib> #include <iomanip> using namespace pcpp;using namespace std;#define MY_FORMAT setw(18) << setiosflags(ios::left) IFileReaderDevice* openFileReader (string fileName) getReader (fileName);if (!openedReader)"Cannot determine reader for file type" << endl;exit (EXIT_FAILURE);if (!openedReader->open ())"Cannot open input.pcap for reading" << endl;exit (EXIT_FAILURE);return openedReader;void printSplitedTuple (string s) int prevFind = -1 ;int nowFind;while ((nowFind = s.find (" " , prevFind + 1 )) != string::npos)substr (prevFind + 1 , nowFind - prevFind);substr (prevFind + 1 );int main (int argc, char * argv[]) "test_file_1.pcap" ;openFileReader (pcapFile);if (!reader->setFilter ("tcp" ))"Cannot set filter for file reader" << endl;exit (EXIT_FAILURE);auto BEGIN = clock ();while (reader->getNextPacket (rawPacket))Packet parsedPakcet (&rawPacket) ;getLayerOfType <TcpLayer>();getLayerOfType <IPv4Layer>();getSrcIPv4Address ().toString () + " " +getDstIPv4Address ().toString () + " " +to_string (tcpLayer->getSrcPort ()) + " " +to_string (tcpLayer->getDstPort ());if (tcpLayer->getTcpHeader ()->synFlag == 1 )insert (pair <string, timespec>(keyTuple, rawPacket.getPacketTimeStamp ()));if (tcpLayer->getTcpHeader ()->finFlag == 1 )auto sessionStart = sessionMap.find (keyTuple);if (sessionStart != sessionMap.end ())"Src" << MY_FORMAT << "Dst" "SrcPort" << MY_FORMAT << "DstPort" "Start" << MY_FORMAT << "End" << MY_FORMAT << "Duration" printSplitedTuple (keyTuple);double startTime = sessionStart->second.tv_sec + (double )sessionStart->second.tv_nsec / 1e9 ;double endTime = rawPacket.getPacketTimeStamp ().tv_sec + (double )rawPacket.getPacketTimeStamp ().tv_nsec / 1e9 ;getPacketTimeStamp ().tv_secsetprecision (5 ) << (endTime - startTime)erase (sessionStart);auto END = clock ();"Total time: " << double (END - BEGIN) / CLK_TCK * 1000 << "ms." << endl;close ();delete reader;return 0 ;
Copy
上面的代码使用了 rawPacket.getPacketTimestamp() 来获取数据包的时间戳,返回结果是一个 timespec 类型!这个类型表示从日历起点到现在所经过的秒数,它的第一部分是 秒 ,第二部分是 纳秒 ,我使用了 秒 来打印会话开始时间和结束时间,使用了 纳秒 来计算会话持续时间。
此外,为了输出结果的美观,我定义了一个 MY_FORMAT 宏,将输出的字符串指定为 18 个宽度,方便对齐。
这次的运行花了5秒多!结果看着蛮厉害,其实问题有很多 😢 这些问题是在我基本上完成了这个程序之后,逐渐意识到的。
元组的表示问题 首先是那个四元组的问题。我们说一个TCP会话是由一个元组确定的,这自然是没有错,但是在编程实现中,我把这四个元素简单地做了字符串拼接,这就带来问题了!本来 (SrcIP, DstIP, SrcPort, DstPort) 这四个元素的顺序是可以倒换的,也就是它跟 (DstIP, SrcIP, DstPort, SrcPort) 是同一个东西啊!更加具体地说,本来由 192.168.0.102 发往 1.1.1.1 的会话是双向的,也就是说 (192.168.0.102, 1.1.1.1, 4321, 443) 这么一个元组表示主机发往服务器的数据,而 (1.1.1.1, 192.168.0.102, 443, 4321) 表示的是服务器发往主机的数据,这两个元组表示的是同一个会话!而我 愚蠢地 做了字符串拼接,而且用这个拼接后的字符串来作为 map 的 key 。这种 key 表示出来的东西根本就不全啊?!会使得我们在取得一个 FIN 包时,只能找到 同向的 SYN 包,也就是说,我们整理出来的会话,只能是 由主机发起、由主机断开 或者是 由服务器发起、由服务器断开 的会话,至于 由主机发起、由服务器断开 的会话,或者 由服务器发起、由主机断开 的会话,就整理不到了。
会话起止的问题 即便解决了元组的表示问题,还有会话起止的问题没有考虑到。
TCP的三次握手和四次挥手中,会产生 两个SYN包、两个FIN包 !这是我在编程过程中遗漏的知识点,反应过来之后,头痛不已……
会话的起止,应该表示为第一个 SYN 和最后一个 FIN ,第一个 SYN 是不含 ack 的,而最后一个 FIN 是在同一个元组下出现的第二个 FIN 。
这样的算法 不考虑超时重传的情况、不考虑最后一个 ack 的传输、不考虑连接断开之前的 2MSL 等待 。
感觉误差挺大的样子,不过这样的误差会作用到每一个会话上,相对来说是可以接受的。
比较成功的会话切分 在上面部分的代码宣告失败后,我翻看PCPP的 示例应用 ,意外地发现了 PcapSplitter 这个好东西,作者已经初步实现了按照会话切分 pcap 文件的功能。
不过,作者的代码只能作为参考,因为他是将一个大的 pcap 文件按照一定规则切分为若干小的 pcap 文件,跟我的主要需求不太一致。
当我阅读 ConnectionSplitter.h 这个文件时,发现了一个重要的函数: hash5Tuple() 。
有没有搞错?!搞了大半天的用四元组来表示一个会话,结果这个库自己就能够处理元组哈希?而且参数简单得要死,传入一个 parsedPacket 即可。
行叭,就用这个函数来替代之前的愚蠢的元组表示方式,同时完善一下会话起止的判定方法,改写一下会话切分代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 #include <iostream> #include <IPv4Layer.h> #include <TcpLayer.h> #include <Packet.h> #include <PcapFileDevice.h> #include <PacketUtils.h> #include <set> #include <map> #include <vector> #include <ctime> #include <cstdlib> #include <iomanip> using namespace pcpp;using namespace std;#define MY_FORMAT setw(18) << setiosflags(ios::left) IFileReaderDevice* openFileReader (string fileName) getReader (fileName);if (!openedReader)"Cannot determine reader for file type" << endl;exit (EXIT_FAILURE);if (!openedReader->open ())"Cannot open input.pcap for reading" << endl;exit (EXIT_FAILURE);return openedReader;int main (int argc, char * argv[]) "test_file_1.pcap" ;openFileReader (pcapFile);if (!reader->setFilter ("tcp" ))"Cannot set filter for file reader" << endl;exit (EXIT_FAILURE);uint32_t , timespec> sessionMap;uint32_t , int > finCount;int outputCount = 0 ;auto BEGIN = clock ();while (reader->getNextPacket (rawPacket))Packet parsedPakcet (&rawPacket) ;getLayerOfType <TcpLayer>();getLayerOfType <IPv4Layer>();uint32_t keyTuple = hash5Tuple (&parsedPakcet);if (tcpLayer->getTcpHeader ()->synFlag == 1 && tcpLayer->getTcpHeader ()->ackFlag == 0 )getPacketTimeStamp ();if (tcpLayer->getTcpHeader ()->finFlag == 1 || tcpLayer->getTcpHeader ()->rstFlag == 1 )if (finCount.find (keyTuple) != finCount.end ())else 1 ;auto sessionStart = sessionMap.find (keyTuple);if (finCount[keyTuple] == 2 && sessionStart != sessionMap.end ())"Src" << MY_FORMAT << "Dst" "SrcPort" << MY_FORMAT << "DstPort" "Start" << MY_FORMAT << "End" << MY_FORMAT << "Duration" getSrcIPv4Address ().toString ()getDstIPv4Address ().toString ()getSrcPort ()getDstPort ();double startTime = sessionStart->second.tv_sec + (double )sessionStart->second.tv_nsec / 1e9 ;double endTime = rawPacket.getPacketTimeStamp ().tv_sec + (double )rawPacket.getPacketTimeStamp ().tv_nsec / 1e9 ;getPacketTimeStamp ().tv_secsetprecision (5 ) << (endTime - startTime)erase (sessionStart);auto END = clock ();"Total time: " << double (END - BEGIN) / CLK_TCK * 1000 << "ms." << endl;"Total sessions: " << outputCount << endl;close ();delete reader;return 0 ;
这次代码作出的改变主要有:
使用 uint32_t keyTuple = hash5Tuple(&parsedPakcet); 来表示会话元组,既节省空间(原先的 String 超级大)又节省时间(把 String 当做键值,比较起来很慢);
重新考虑会话起止的算法。会话起点为带有 SYN 但不带 ack 的包,会话终点为第二个 FIN 包;在后期观察时,发现 会话终点还可以是 RST 包 。
结果不坏。从时间上看,基本上比之前的切分方式快了一倍。
与WireShark统计结果的对比 程序计算出来的结果是 163 个完整会话,而WireShark的统计结果是 221 个会话:
但是将这些会话按照字节大小排序,跟踪前面的比较小的会话,发现这些会话并不完整:
我推测WireShark仅仅是根据五元组来进行统计,根本没有去考虑会话的完整性。如果我们使用 hash5Tuple() ,计算出来的每一个 uint_32 值都表示一个会话,那么结果跟WireShark的统计应该是一样的。
简单在代码中添加一个记录这些五元组的集合 set<uint32_t> tupleSet; ,然后每计算一个哈希值就往里放,最后打印一下:
果不其然!
WireShark这种统计方式没什么用啦!一个没头没尾的数据段能代表什么呢?还是按照之前提到的方法来表示一个会话,这样精确一点!
参考资料 [1] 4. Packet Parsing - PcapPlusPlus
[2] 1. Introduction - PcapPlusPlus
[3] PcapPlusPlus: API Documentation
[4] 一站式学习Wireshark(七):Statistics统计工具功能详解与应用 - zhuimeng~ - 博客园 (cnblogs.com)
[5] PcapPlusPlus/Examples/PcapSplitter at master · seladb/PcapPlusPlus (github.com)
技术 计算机网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 #include <iostream> #include <fstream> #include <string> #include <vector> #include <unordered_map> #include <pcapplusplus/IPv4Layer.h> #include <pcapplusplus/Packet.h> #include <pcapplusplus/PcapFileDevice.h> #include <pcapplusplus/TcpLayer.h> #include <filesystem> using namespace std;using namespace pcpp;namespace fs = std::filesystem;struct SessionKey {uint16_t srcPort;uint16_t dstPort;bool operator ==(const SessionKey& other) const {return srcIp == other.srcIp && dstIp == other.dstIp && srcPort == other.srcPort && dstPort == other.dstPort && protocol == other.protocol;namespace std {template <>class hash <SessionKey> {public :size_t operator () (const SessionKey& key) const return hash <string>()(key.srcIp.toString () + key.dstIp.toString () + to_string (key.srcPort) + to_string (key.dstPort) + to_string (static_cast <int >(key.protocol)));int main (int argc, char * argv[]) if (argc < 3 ) {"Usage: " << argv[0 ] << " <input pcap file> <output directory>" << endl;return 1 ;1 ];2 ];getReader (inputPcapFile);if (!reader) {"Cannot determine reader for file type" << endl;return 1 ;if (!reader->open ()) {"Cannot open " << inputPcapFile << " for reading" << endl;return 1 ;try {create_directories (outputDir);catch (const fs::filesystem_error& e) {"Cannot create output directory: " << outputDir << endl;"Error: " << e.what () << endl;return 1 ;while (reader->getNextPacket (rawPacket)) {Packet parsedPacket (&rawPacket) ;if (parsedPacket.isPacketOfType (pcpp::IPv4) && parsedPacket.isPacketOfType (pcpp::TCP)) {getLayerOfType <IPv4Layer>();getLayerOfType <TcpLayer>();getSrcIPv4Address (),getDstIPv4Address (),getSrcPort (),getDstPort (),push_back (rawPacket);close ();for (const auto & session : sessions) {"/" + session.first.srcIp.toString () + "_" + session.first.dstIp.toString () + "_" + to_string (session.first.srcPort) + "_" + to_string (session.first.dstPort) + ".pcap" ;PcapFileWriterDevice writer (sessionFileName, LINKTYPE_ETHERNET) ;if (!writer.open ()) {"Cannot open " << sessionFileName << " for writing" << endl;continue ;for (const auto & packet : session.second) {writePacket (packet);close ();return 0 ;
g++ splitpcap.cc -o splitpcap -I /usr/include/pcapplusplus -L/usr/lib/pcapplusplus -lPcap++ -lPacket++ -lCommon++ -lpcap
session2png
1 2 3 4 5 CFLAGS = `pkg-config --cflags opencv4`$(CFLAGS) $(LIBS) -o $@ $< -lvtkCommonCore
./2.PreprocessedTools/splitpcap ./1.DataSet/vpn_aim_chat1a.pcap 2_Session/L7



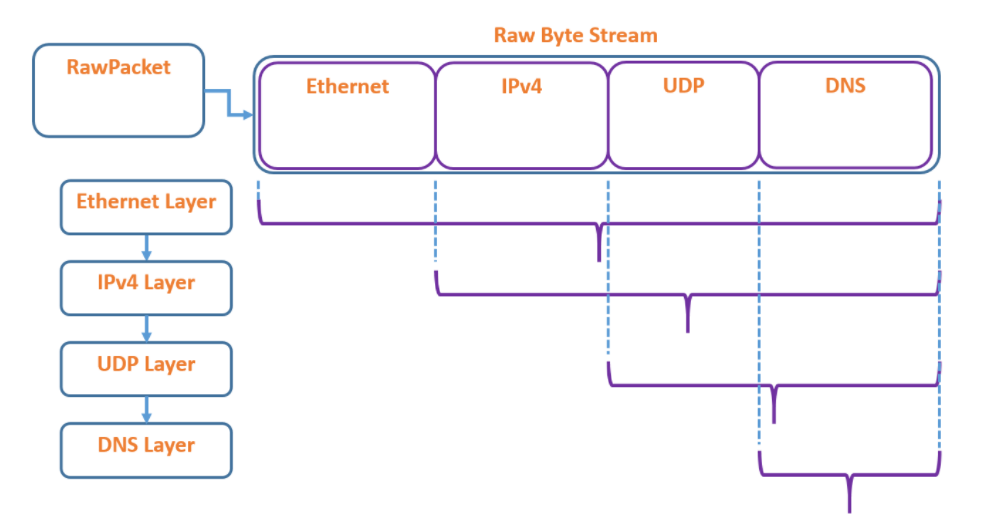 示例
示例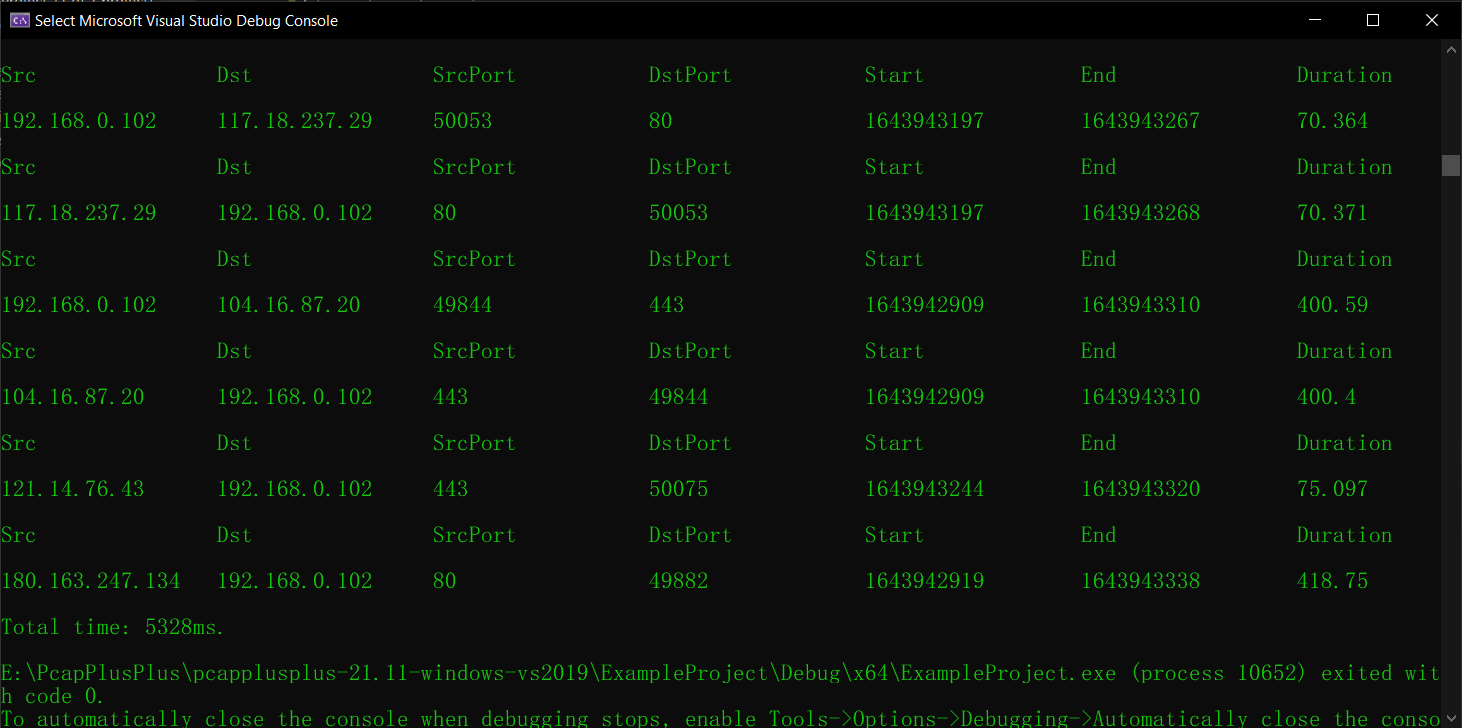 输出结果
输出结果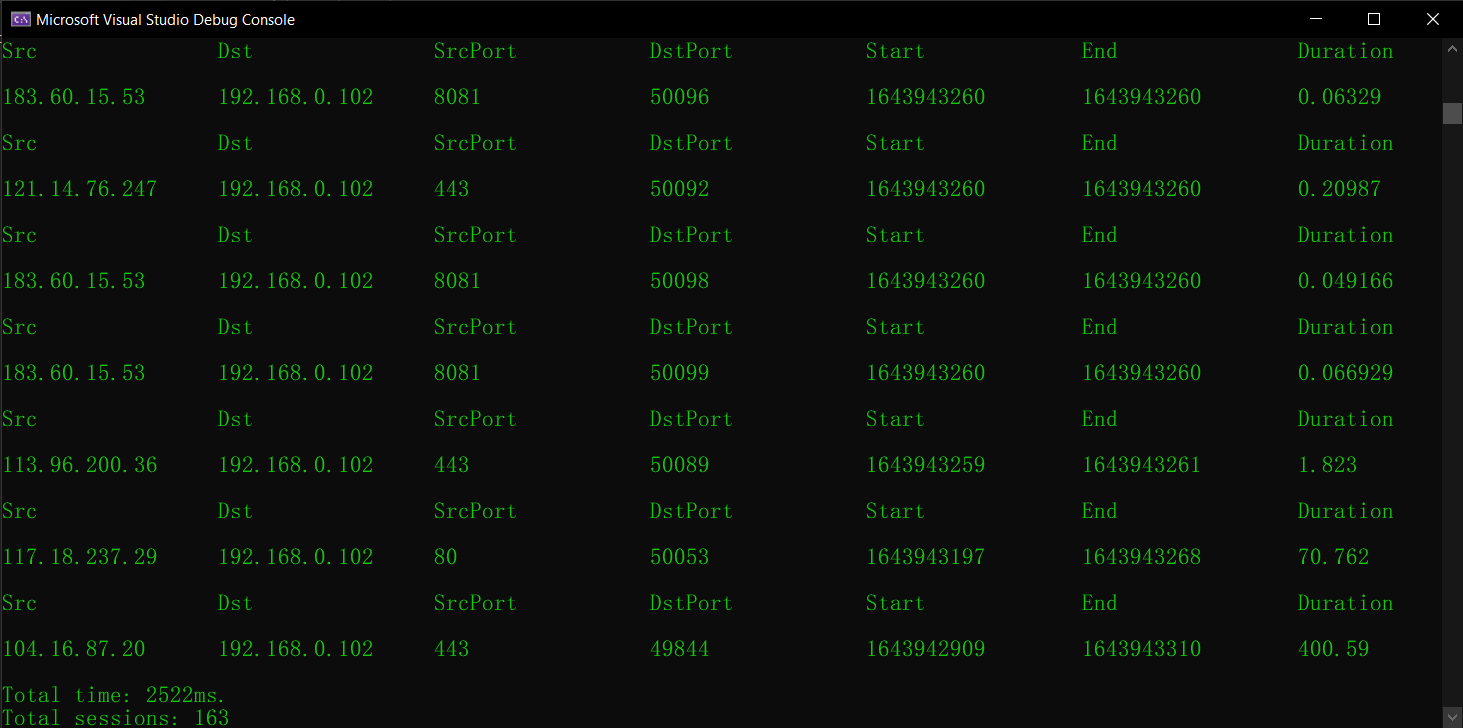 运行结果
运行结果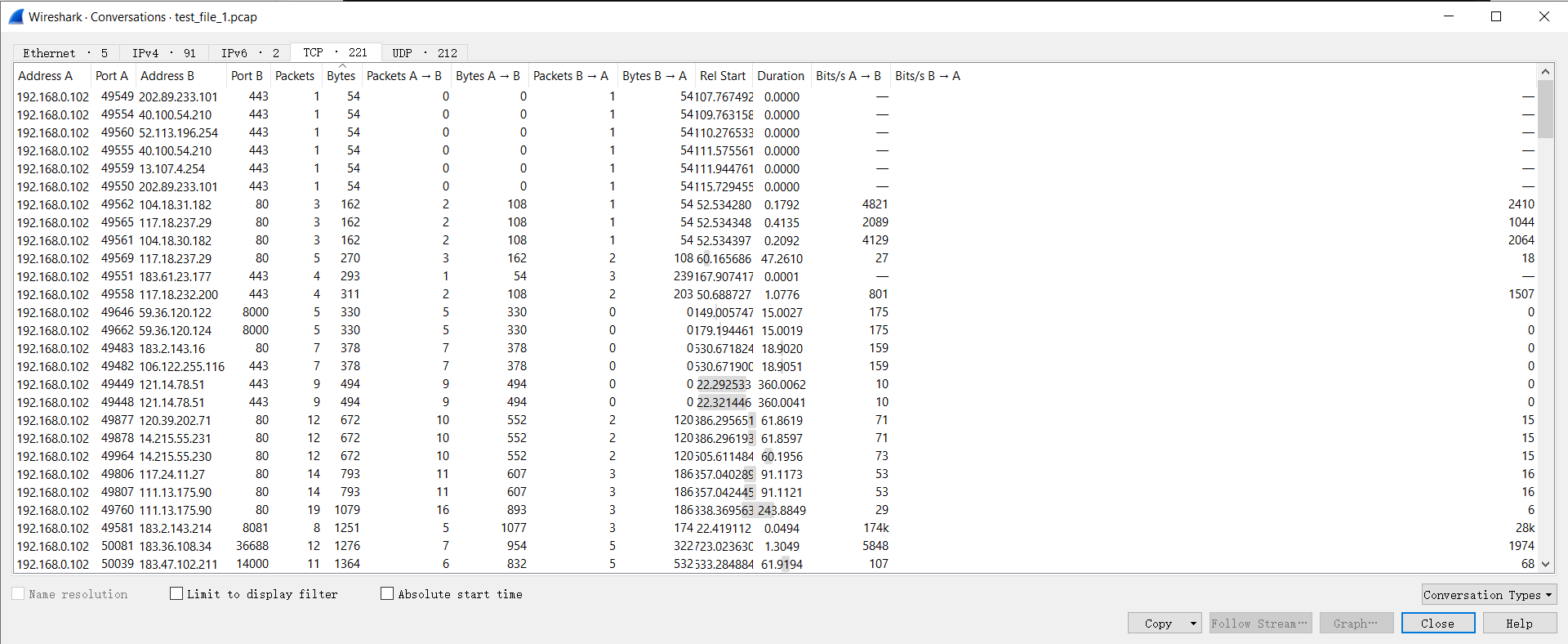 WireShark–Statistics–Conversations
WireShark–Statistics–Conversations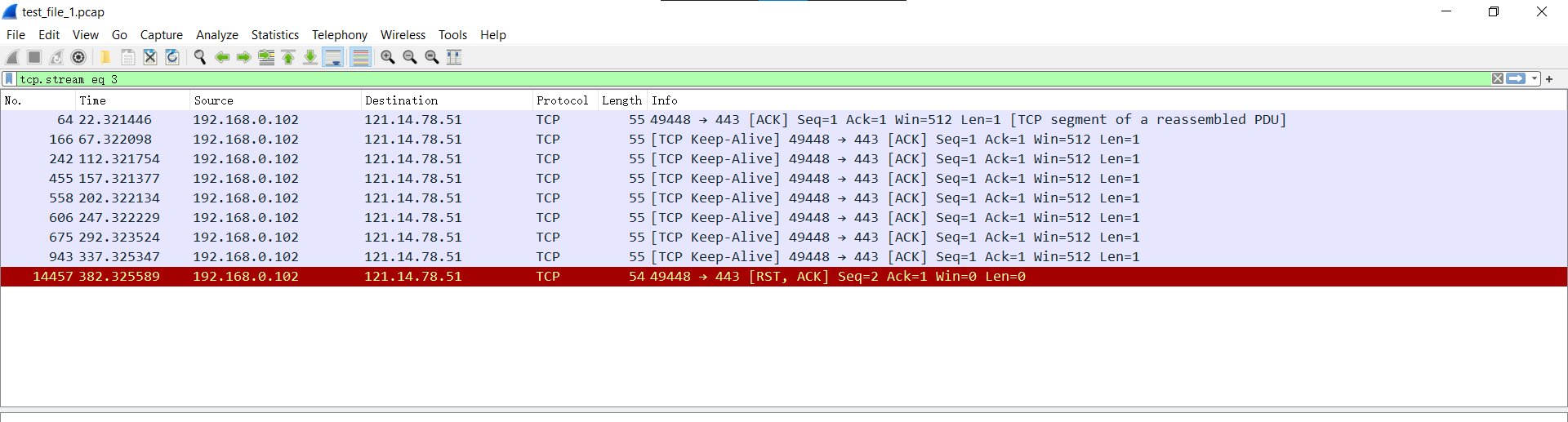 不完整的会话
不完整的会话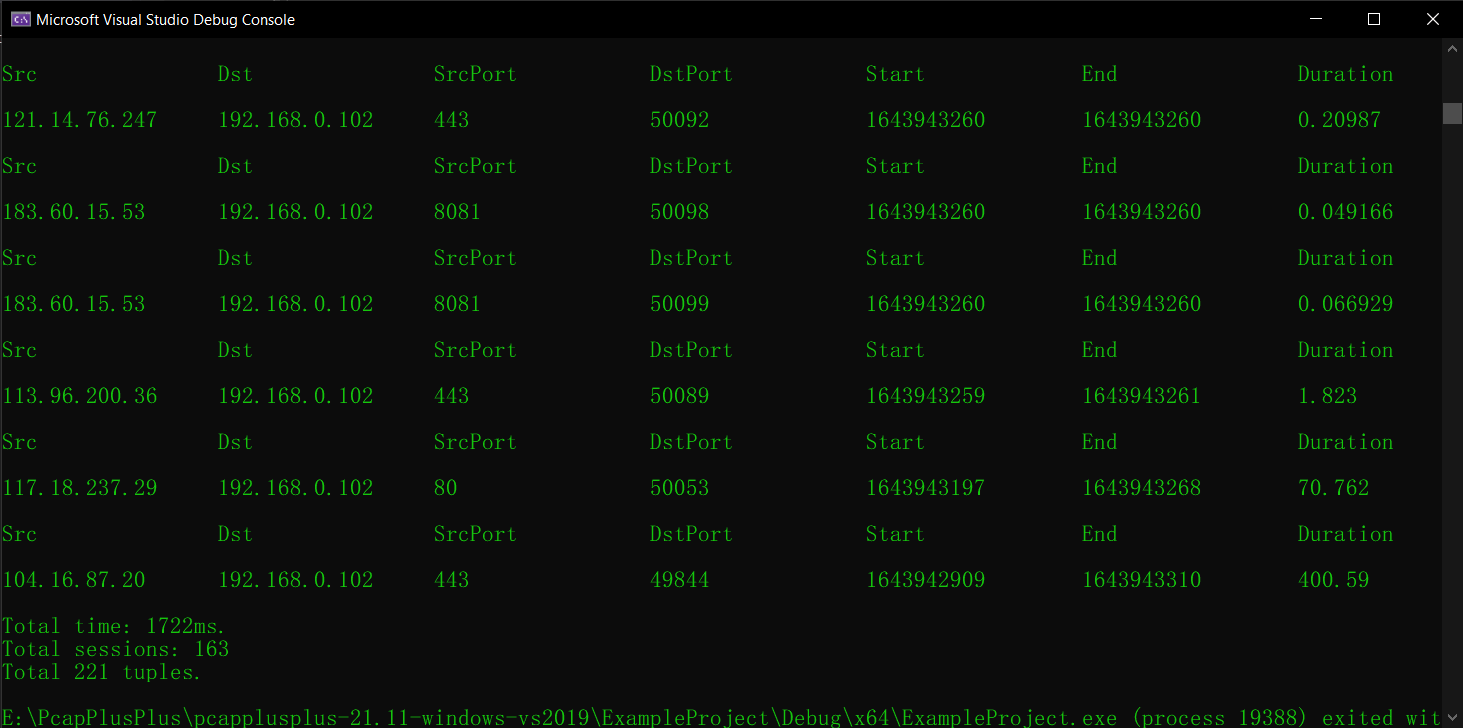 tupleSet.size()
tupleSet.size()